
ブログ
Memsourceは初めてですか?

Christophe Eyraud、Semantix社ソリューションアーキテクト
2018年1月、Memsourceは同社初のAI搭載機能であるAIによる翻訳不要箇所検出機能(Non-tranlatables、略称NT)をリリースしました。翻訳コンテンツをスキャンして、翻訳不要なセグメントを自動的に検出できる機能です。これによって実質的な翻訳量を減らせるため、翻訳をより速く、より低コストで行えます。
Semantixはこれを早期に採用した企業のひとつで、私はこの機能をSemantixの実際の翻訳プロジェクトに試験導入しました。このケーススタディでは、私の発見をいくつか紹介したいと思います。
重み付けされた単語数について理解する
まずケーススタディに入る前に、翻訳ツールがどのように機能するかを簡単に説明する必要があるでしょう。翻訳ツールには、_翻訳メモリ_という、過去に翻訳された _セグメント_のデータベースが含まれます。1セグメントは、1センテンスだとしましょう。複数のセグメントが入ったファイルを翻訳する前に、最初にファイルを_解析_する必要があります。
解析では、翻訳するファイルのセグメントと翻訳メモリのセグメントを比較します。再利用できる翻訳済みのセグメントが多ければ多いほど、翻訳にかかるコストは抑えられます。解析によって、全く同じセグメントのため編集の必要がない、あるいはわずかな編集しか必要ないセグメントの数(100%一致)、ほとんど同一であるが一部編集が必要なセグメントの数(ファジーマッチ)、翻訳メモリに存在しないためゼロから翻訳する必要があるセグメントの数(マ ッチなし)がそれぞれ検出されます。
解析レポートには、_重み付けされた単語数_も含まれます。それは、それぞれのカテゴリーに含まれる単語数に、一致率ごとの割引率をかけて算出されます。(100%一致の場合は、ファジーマッチよりも安価になります。ファジーマッチの場合は、マッチなしより安価になります。)重み付けされた単語数を見れば、ファイルの翻訳に必要な時間と労力を見積もることができます。
したがって、ファイルを翻訳するときに重要なのはファイル内の単語数ではなく、ファイルを解析した後に取得できる重み付けされた単語数になります。
コスト削減に実効性を
これはMemsourceが新たに導入したAIによる翻訳不要箇所の検出機能とどのように関連するのでしょうか?MemsourceのCEOであるDavidČaněkによると、Memsourceのデータは全体のセグメントの14%(これは、全セグメントのワード数の4%に相当)が翻訳不要箇所であると示しています。これらは、企業名、製品名、数字、さまざまなコードなど、翻訳の不要なセグメントになります。従来のルールベースのアルゴリズムにおいても、翻訳不要箇所は検出されますが、特定できる数は限られています。
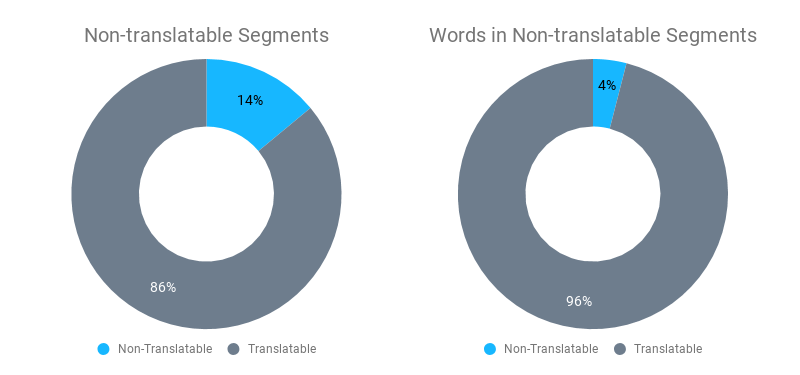 そこでAIの出番です。AIを使えば、より多くの翻訳不要箇所を検出できるだけではなく、先ほど述べた解析レポートで使用されるスコア設定を翻訳不要箇所にも適用できるようになります。(これにより_100%翻訳不要箇所一致_や_ファジー翻訳不要箇所マッチ_ができます)。ご存知のように、100%一致やファジーマッチは、マッチなしの場合より少ない編集で済みます。つまり、Memsourceの新機能は、重み付けされた単語数を減らし翻訳にかかるコストを低減させることに役立ちます。
そこでAIの出番です。AIを使えば、より多くの翻訳不要箇所を検出できるだけではなく、先ほど述べた解析レポートで使用されるスコア設定を翻訳不要箇所にも適用できるようになります。(これにより_100%翻訳不要箇所一致_や_ファジー翻訳不要箇所マッチ_ができます)。ご存知のように、100%一致やファジーマッチは、マッチなしの場合より少ない編集で済みます。つまり、Memsourceの新機能は、重み付けされた単語数を減らし翻訳にかかるコストを低減させることに役立ちます。
今回のケーススタディでは実際のプロジェクトに基づき、さまざまなドキュメントタイプと言語を扱いました。目的はどのようなセグメントが翻訳不要箇所として特定されるかを検証すること、提案された翻訳不要箇所と翻訳者による最終的な訳文を比較することでした。また、多くの翻訳不要箇所を含むテストファイルを使って、この機能によって翻訳不要箇所があらゆる言語でどのように分類されるのかを調べました。ケーススタディの全体的な目標は、この機能の信頼性を確保することだけでなく、とりわけこの機能がSemantixや他のMemsourceユーザーに与える利点は何かを検証することでした。
AI搭載の翻訳不要箇所検出機能の検証結果
この機能は、従来よりはるかに多くの翻訳不要箇所を検出します。数字とタグ(文字を含まないセグメント)に加えて、頭字語、英数字の文字列、メールアドレス、URL、名称(都市、場所、人、企業名)などが含まれるようになりました。
| 略語 | 非テキスト要素 | アドレス | 数字 | 英数字の文字列 | その他の名称( 団体・企業) | コード | 電話番号 | 人名 | 地名 | 日付 | 番号 | 10進数の数字 | タグ | メールアドレス | 年代 | 測定値 | URL | その他 | 変数 |
AIによる翻訳不要箇所の検出
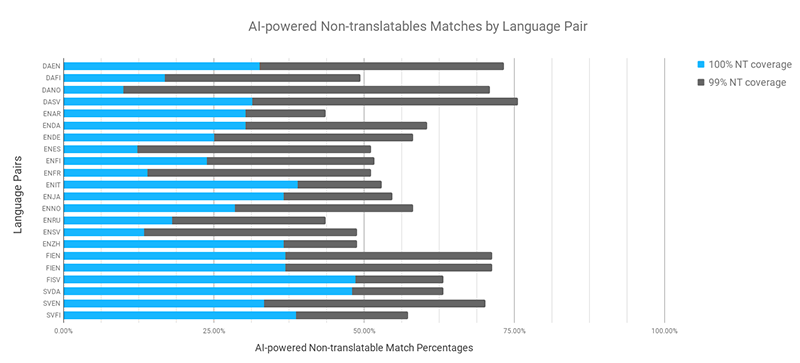
翻訳不要箇所はテクニカル文書(カタログ、マニュアルなど)に多く見られますが、マーケティング文書、メディカル文書、財務文書でも良い結果を得られることがわかりました。もちろんすべての言語が同じように扱われるわけではないので、翻訳不要箇所として検出される単語の数や種類は言語によって様々でした。たとえば、ターゲット言語が英語の場合、カバレッジの合計は高くなります(米語、英語に問わず)。
ある言語ペアでは、NTの100%一致の数は少なくなった一方で、より多くの数のNTの99%一致が検出されました。これは、その言語に関するモデルが明確でない場合に生じます。NTの100%一致を提案する代わりに、保守的なアプローチが適用されてNTの99%一致として分類されます。今回注目したいことのひとつは、フィンランド語が劣っていなかったことです。カバレッジの合計ではフランス語と等しいものでした。
上記で説明したように、100%一致というのは少しの編集あるいは編集をまったく必要としないセグメントで、ファジーマッチは常に何かしらの編集が必要なセグメントのことです。今回、AIによって検出された翻訳不要箇所に関して言えば、ケーススタディのプロジェクトでNTの100%一致と検出されたセグメントのうち94%は編集をまったく必要としませんでした。
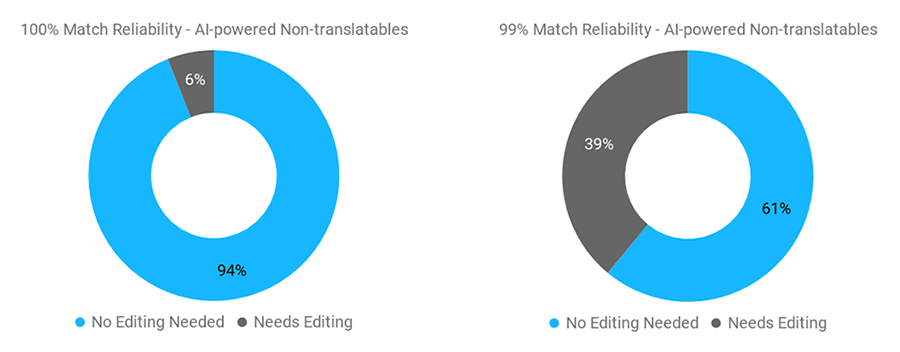
これは良い知らせです。つまり、NTの100%一致は、通常の翻訳メモリの100%一致と同じであると見なすことができます。コンテキスト(前後の文脈)に基づいて編集する必要が生じる場合もありますが、ほとんどの場合、編集を必要としないということです。他にも良い知らせがあり、NTのファジーマッチのうち61%のセグメントは編集の必要がありませんでした。それは嬉しい驚きでした。定義上、ファジーマッチというのは編集を必要としますが、NTのファジーマッチの場合、10のうち6のセグメントは編集が要らないものでした。
結論:実効性はあったのか?
一言でいうと、AIによる翻訳不要箇所検出機能は信頼性が高く、プロジェクトの重み付けされた単語数を減らすことができたということです。このようにして、以前より早く翻訳を納品でき、他社に負けない価格を提示できます。AIによる翻訳の不要な単語数の検出機能を備えた解析機能を活用することで、翻訳の不要なコンテンツについては課金されないことがお客様にはっきりと伝わります。これは、Semantixにとって非常に重要なことです。この新機能は、お客様との関係性を高め、私たちの信頼を高めます。
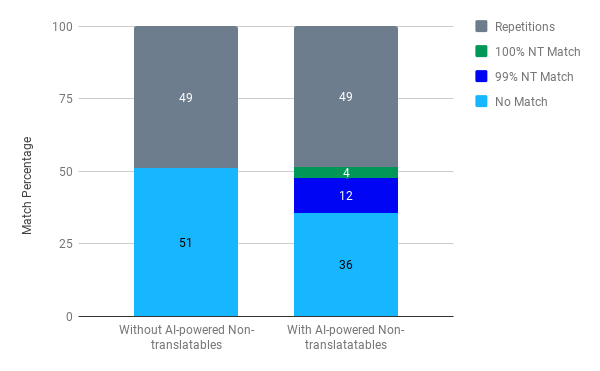
供給側がコストを削減することも重要です。最近のプロジェクト(下の図)では、単語数は150,000語あり、フランス語の翻訳向けに当初重み付けされた単語数は87,000語でした。翻訳不要箇所の検出機能を導入すると、重み付けされた単語数は65,000語まで減少しました。下のグラフからわかるように、翻訳不要箇所の検出機能を使用しなければ、セグメントの49%は繰り返され、51%はマッチなしと検出されます。AIを活用した翻訳不要箇所の検出機能を導入すると、マッチなしのセグメントの数は36%となり、15%減少したことになります。本来フランス語の翻訳者に約13,035ユーロを支払うところでしたが、翻訳不要箇所の検出機能を導入した結果、そのコストは9,689ユーロまで減少しました。多言語プロジェクトで達成できるコストの削減額を想像してみてください。
この機能には翻訳者にとってもプラスの影響があります。翻訳不要箇所の検出スコアのおかげで、一部のセグメントに対しては他のセグメントより少ない注意を払えば良く、スタイルと創造性に集中できるので、結果として生産性を向上させることができるとわかっています。
もちろん、この機能は賢く使う必要があります。言語の組み合わせ、ソースコンテンツ、翻訳不要箇所として予想されるタイプは何かなど、方程式にあるさまざまな要素を考慮するために、いくつかテストしてみる必要があります。次に、式を調整したり、それに応じて重み付けされた単語数の計算に使用される割引率を照合したりする必要があります。
そうは言っても、AIを活用した翻訳不要箇所の検出機能に大きな可能性があることは確かです。今後の可能性は?購入コストを削減し、お客様との関係性を高めます。
著者について:
{:.ov-h} {:.float-right} Christophe Eyraudは、北欧最大の翻訳会社であるSemantixのソリューションアーキテクトです。Christopheは、業界の動向を常にウォッチし、テクノロジープロバイダとの良好な関係に支えられ、Semantixの顧客によるローカライゼーションワークフローの付加価値の提供を支援するソリューションを設計、実装しています。
{:.float-right} Christophe Eyraudは、北欧最大の翻訳会社であるSemantixのソリューションアーキテクトです。Christopheは、業界の動向を常にウォッチし、テクノロジープロバイダとの良好な関係に支えられ、Semantixの顧客によるローカライゼーションワークフローの付加価値の提供を支援するソリューションを設計、実装しています。
Semantix社について:
{:.float-right} ![]()
Semantixは北欧最大の言語会社であり、50年以上にわたって公共部門と民間企業に通訳、翻訳、高度な言語ソリューションを提供しています。Semantixの売上高は約9億クローネで、ISO 9001:2015に準拠して運営しています。同グループはスウェーデン、デンマーク、ノルウェー、フィンランドにオフィスを持ち、中国、チリ、スペインに代理店を置いています。Semantixには約400人の従業員がおり、世界中の何千もの言語のスペシャリストとネットワークを構築しています。Semantixの株式は、プライベートエクイティファンドのSegulah V L.Pが過半数を所有しています。詳細は、_www.semantix.eu_をご覧ください。


