
Blog
Contents
Machine Translation Report
What is the optimal MT Engine for you? Find out in the latest MT Report by Memsource.
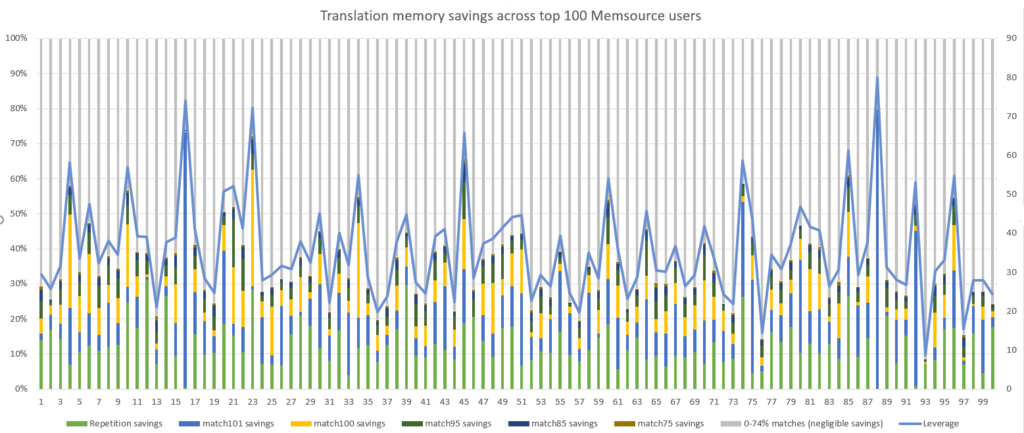
Savings from translation memory for top-100 users in Memsource, sample size 516 million words
For our second Translation Big Data study, we’ve investigated how owning translation memory increases productivity and saves money.
The table above applies a predefined net rate scheme to a sample of 500+ million words. It clearly shows that Memsource’s most active users increase their productivity up to 36% by using translation memory. This means that if you had an average cost of 10 euro cents per word, for this volume you could save €18.6 million. Not bad!
What is translation memory
Translation memory is the core benefit of CAT-tools. It brings potentially huge savings to users through the reuse of past translations.
TM breaks the translation text into small parts called segments. It then saves the translation of each segment, so that next time you can just paste it from the memory.
Contracts, user interfaces, and manuals have many repetitive parts. Once you translate one or two of these, most of your work on future versions of these documents are already done. It‘s sufficient just to paste the saved text from memory, change a few words and names here and there, and voila - your translation is ready at 10% of the cost and time.
When running teams of linguists, TM helps to maintain terminology uniformity across large volumes of text. If you translate Microsoft Windows, for example, the names of the buttons will stay the same no matter how many people work on it. If you translate a huge video game, characters and items will be named appropriately in each version of the product.
In short, TM is invaluable in professional translations; 85.2% of jobs created in Memsource are enabled with TM.
Our Calculation
For this sample, we took the last 6 months-worth of translations from our top-100 users. These are mostly large translation companies and in-house translation departments at software and manufacturing enterprises.
We cleaned up the data, and used only the parts which matched the following criteria:
- User applied translation memory and created an analysis
- No net rate scheme applied
- Jobs were marked as complete
- First workflow step only (translation but not editing)
This resulted in a rather impressive sample of 516.5 million words (879 times bigger than Leo Tolstoy’s War and Peace and almost 4,000 times bigger than A Tale of Two Cities by Charles Dickens).
![]()
Memsource’s translation memory works by checking how similar the new segment is to the best available match in the TM. It classifies the segments into 8 categories
| Classification | Words belong to… |
| Repetitions | A segment that is repeated within the translated document |
| match101 | A context match: 100% match preceded and followed by other 100% matches |
| match100 | A segment is identical to a segment in the TM |
| match95 | 99-95% similarity |
| match85 | 85-94% similarity |
| match75 | 75-84% similarity |
| match50 | 50-74% similarity |
| match0 | 0-50% similarity |
As you can see, more than half of the text is significantly similar to the parts saved in the translation memory, which may seem almost too good to be true. However, in reality, translators can only save time with good quality matches.
They can confidently insert direct repetitions, i.e. 101% and 100% matches, with minimal checking necessary. However, progressively more time needs to be spent editing fuzzy matches. Matches below 75% generally take too much time to edit, and it is usually easier to translate from scratch in these cases.

In order to calculate your productivity increase, it is common to apply a net rate scheme to the results. Every translation company uses their own table for customers and translators, sometimes gaining margins in between. For our calculation, we used the standard, or “Predefined” net rate scheme available in Memsource.
We applied this table to the number of words in each match category and arrived at the total sum of the savings, which we then compared to the total volume of words translated.
The resulting cost savings range from 14% to 90%. The average value for the whole volume is 36%, and the median across all organizations is 33%.
Calculate your ROI from TM
So, how do you know at what point your organization should buy a translation memory tool? This question can now be easily answered by creating an average savings ratio.
Quite simply, translation memory will be a good investment if the cost savings from using it exceed the cost of the tool.
Memsource starts at €20 per month for a freelancer, and €130 per month for an organization.
With an expected saving of 36%, you will be able to cover the cost of the software if you spend more than €360 per month on translations. If the current translation budget is even bigger, you should be able to save money with translation memory.
Please bear in mind that it takes time to build up effective TM; for the first few months you will receive the benefit of repetitions only. Our corpus repetitions make 12.5% of the total volume. Consider this when planning your budget.
How to check your own TM leverage in Memsource
To do this, you will need to install Kibana. Follow the instructions on our Wiki, or check out this webinar ”How to visualize your data in Memsource” (minute 11 and on). Once Kibana is up and running:
- Press visualize, then create a new visualization
- Choose
com.memsource.web.analytics.data.analysisas your index pattern - For Y axis, create a set of metrics “
Sum of data.repetitions.words”, thenmatches from 101 to 0. - For X axis, create Date Histogram. Use monthly, weekly or daily according to your requirements.
- Add the following syntax to the command prompt. It selects jobs marked as analyzed and completed for calculation, and removes data to which a net rate scheme has been applied.
jobPart.status:("COMPLETED","COMPLETED_BY_LINGUIST") AND jobPart.level:1 AND !priority:0 AND analysis.tags:"com.memsource.analysis.jobPart.raw" - Remember to select a long period of time (i.e. a month to a year) for the visualization to render correctly.
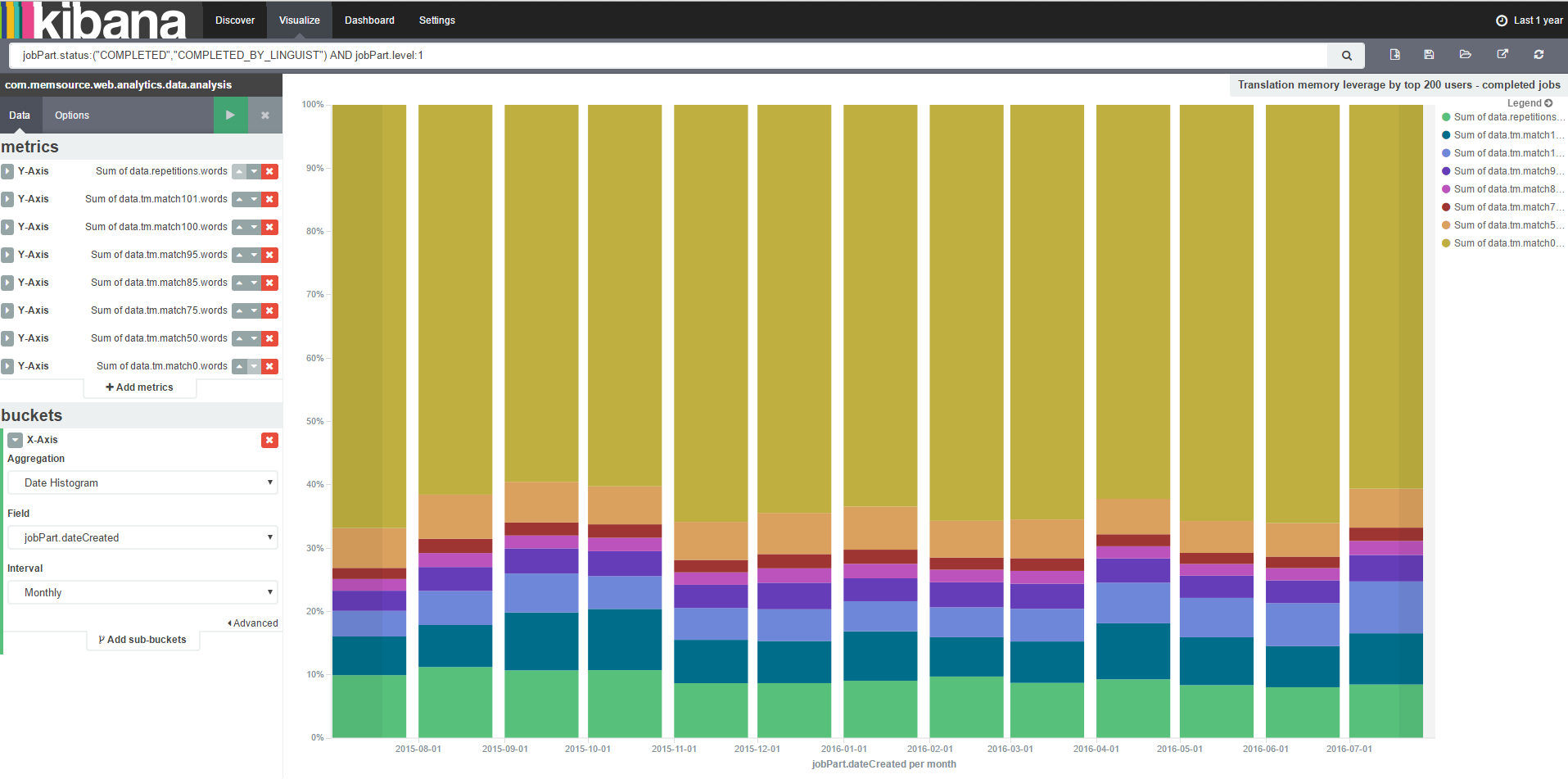
Here’s a screenshot of the complete setup. click to enlarge
You can use the chart to track your budget or cost savings efficiency. You can then predict margins and create financial models ahead of time.
If you are an LSP Solution Partner and you manage a Memsource account, this data could be a powerful differentiator when communicating your value to the procurement department or the CEO.
How to maximise productivity gains from TM
Translation memory is most effective on repetitive texts, such as user manuals, specifications, user interfaces, and support documentation for successive versions of the same software. If your content fits one of these categories, it is possible to get much higher than average leverage over time. We recommend the following practices:
- Prepare the source text. Reuse existing texts when creating new manuals and brochures. Proofread for mistakes. Make sure terminology is consistent.
- Centralise translation memory. Make sure every translator and editor is working within the CAT-tool with the same TM and terminology base.
- Maintain the translation memory by cleaning it from time to time. Your most experienced editor should do it.
- Avoid contaminating your TM. When working on a project with real-time translation memory updates and multiple translators, use two memories. Read from the master TM and write to the new one. Merge TMs once the new TM has been checked by the editor and proofreader.
Large Enterprise buyers may achieve 80-98% leverage
Buyer organizations get the best leverage on translation memory. They often work with successive updates for the same products or product families. The text doesn’t change much with each new version, meaning the memory is highly effective.
There are numerous stories of huge savings made through TM. In 2012 for example at TFR, Kaspersky Labs presented a case study in which they reduced their budget for one product 10 times in 2 years.
At Lockit conf 2013, Iouri Tchernoousko from Adobe showcased the amazing story of how they localized Photoshop, and were able to bring the cost down from $2.5 million for PSC2 in 2004, to $0.5 million in 2013. At the same time, they were able to increase the number of regions covered from 15 to 27+, and they eradicated the previous four-month delay in getting Photoshop localized from English into various other languages.
At our Enterprise Translation Trends webinar in 2015, Mika Pehkonen from F-Secure included a slide showcasing a 90% leverage on TM, and Loic Dufresne de Virel, a localization strategist at Intel Corporation, mentioned a whopping 98% reuse.
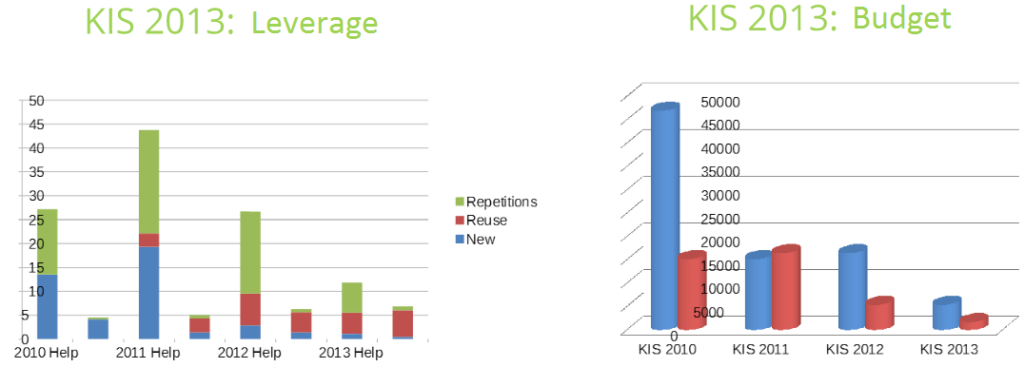
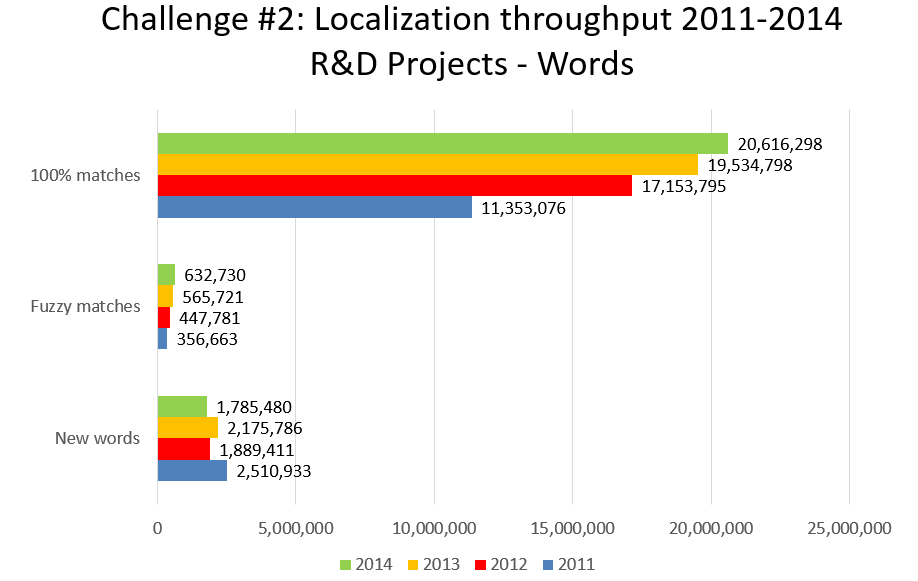
- Kaspersky Internet Security localization budget reduced about 10 times in 4 years. 2. Translation memory reuse at F-Secure: 1.7 m new words vs 20.6 m complete matches in 2014. (click to enlarge)
So as you can see, the 36% saving we demonstrated in this study is very realistic, and in fact, you can potentially do much better than this if you work with the same languages and similar content year to year. In contrast with buyers, translation companies have a lower average reuse rate because they work with new content all the time, and add new languages regularly.
Final word on post #2 in the Translation Big Data series
For professionals in the translation industry, much of the data here might be nothing new; after all, translation memory has existed for more than 20 years, and all major localization buyers already take advantage of it.
However, this is the first time in recent history that someone has been able to measure the effect of TM across multiple organizations on a language corpus of such volume, meaning that what were previously just slogans and declarations (“Save 40%!” “Instant ROI!”) are now proven facts.
Next time, we plan to look at file types and language volumes in Memsource - if you have an interesting idea for future Translation Big Data posts, please contact us at marketing@memsource.com
About the author
![]() Konstantin Dranch is the former head of marketing in Memsource.
Konstantin Dranch is the former head of marketing in Memsource.
His background is in market research. Konstantin has surveyed translation service markets in Russia and Ukraine since 2011 via translationrating.ru, and has recently started similar surveys in the United Kingdom and France.


